
Shortly after Kobe Bryant retired a couple of years ago, Kaggle released a dataset containing 20 years worth of his shots. That’s a lot of swish and I am thinking: Basketball and data science… What more can you ask?
So here is an article on how to build a simple classification model to predict if it’s in or rim. I first published it at Towards Data Science on Medium. The aim is to discuss the intuitions and the practices one can leverage end-to-end, step-by-step, from data exploration to model tuning and finally evaluation. Emphasis also on simple. A decision tree (that’s what we are building) will not win you a competition but the process of building a simple model might also be 80% of the whole work in real-world situations.
Time for data action…
1. Tools and process
I will be using Pandas, Jupyter Notebooks and Scikit-Learn. For the visualisations, I will use Seaborn and Graphiz. I will also briefly use Tableau for fast exploration (it is definitely not necessary though, you can use Python’s tools for the same, I just happened to have it handy and thought I’d try it).
Here’s what follows on a high level: We’ll start by exploring the dataset and visualising it. We’ll clean it and split it to training and testings sets. We’ll model with a decision tree and for this we’ll find the bias/variance sweet spot. We will visualise it and finally evaluate it.
2. Understanding the dataset
The first step is to explore the dataset at hand. This file is provided by Kaggle: data.csv. We only know that theshot_made_flag field is the target variable: Its value is 1 if Bryant scored that shot and 0 if he failed it. Everything else remains to be investigated.
The necessary imports for facilities that will be used throughout the project:

Let’s start the exploration by using the typical Pandas facilities: info() and describe().
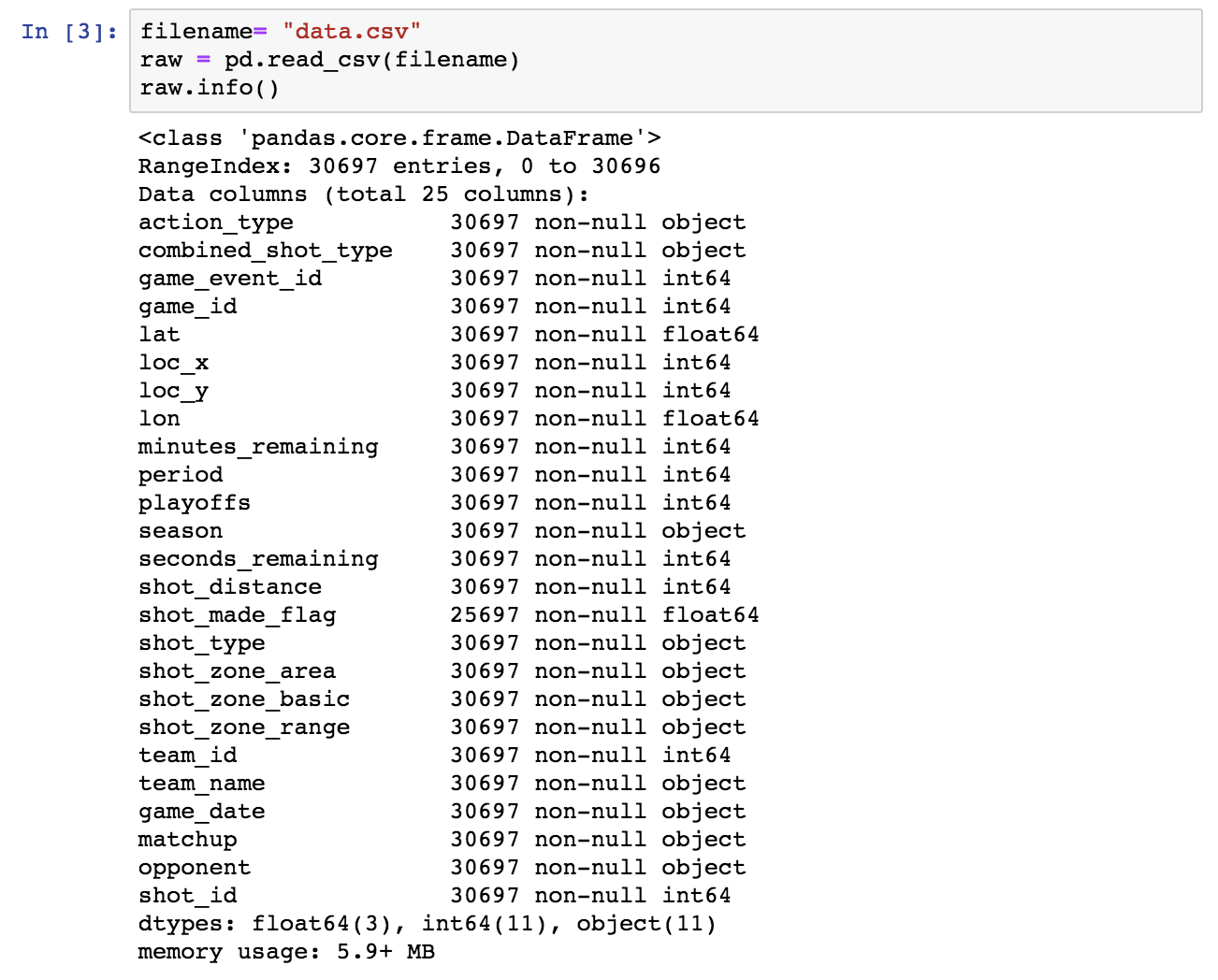
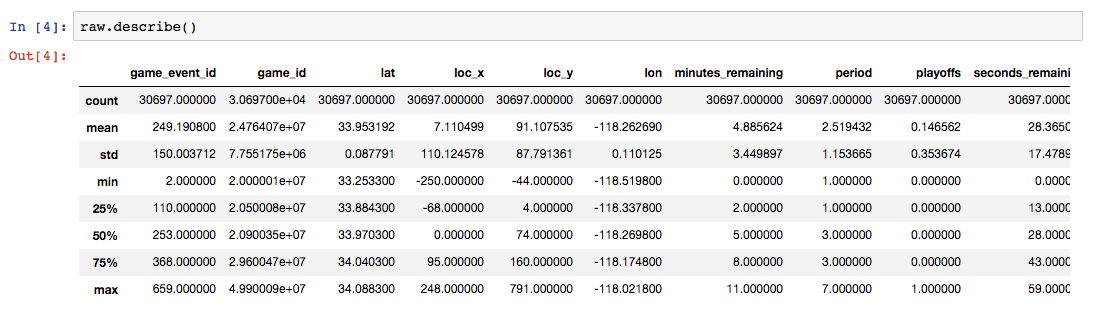
Next, let’s drop the rows in which shot_made_flag has null values, as they are not useful for either training or testing. We will use a new dataframe for the cleansed data.

Of the initial 30697 rows, 25697 remain and 5000 are dropped.
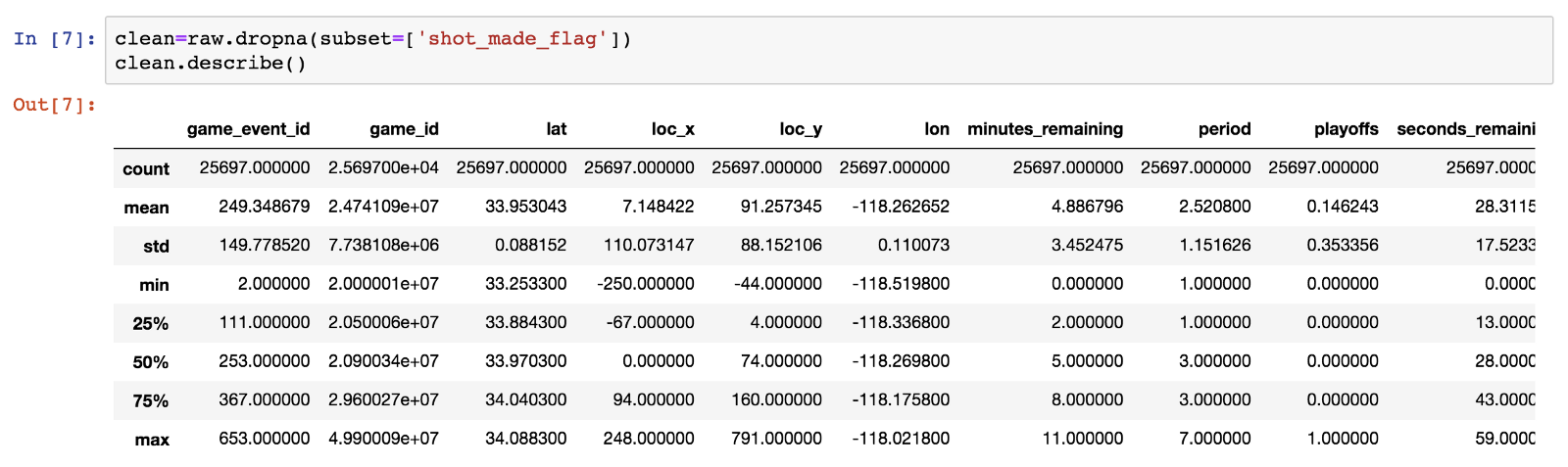

We observe that minutes_remainingtakes values from 0 to 11, so we conclude that this is the time in minutes remaining until the end of each of the four 12-minute periods. Seconds_remaining take values from 0 to 59 as expected.
Let’s combine the two fields to the time_remaining in seconds until the end of each period and add it to the dataframe (see the bottom of the info() list and the row count being 26).

Let’s now have a closer look to check the distinct values of the categorical fields.

Apparently action_type is a finer-grained categorization of combined_shot_type.
Next, let’s check the court area variables.

The first two fields are area categorisations, while the last is the distance in “buckets”. We will map these areas of the field in the next section.
3. Data visualisation
Here is where the good fun starts. Visualising the data is probably the most important part. I will use a bunch of Pandas features.
Let’s first check whether the loc_x, loc_y, lon and lat fields signify the coordinates of each shot, as suspected, and if there is a reason we have four parameters instead of just two. For the rest of our analysis, blue color designates a successful shot (shot_made_flag==1), and red color designates an unsuccessful shot.


Observe that the two plots look like mirror images. I’ll get back to this later on.
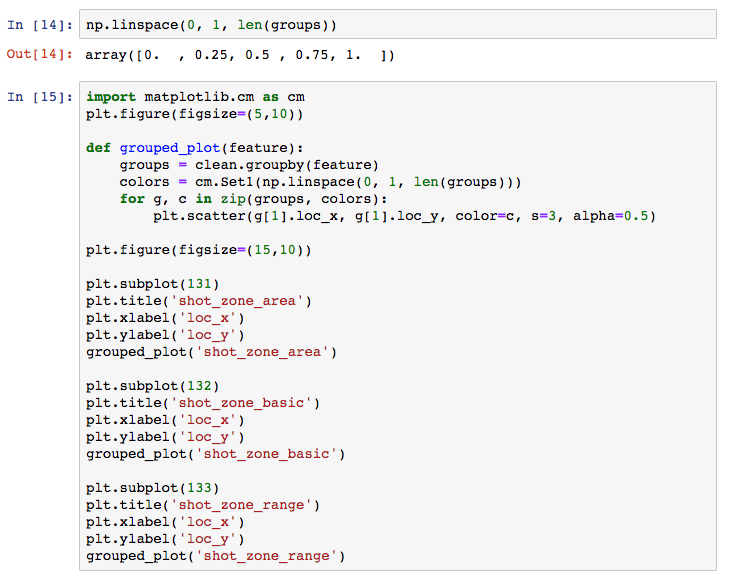
I will next check whether the area-related fields signify different areas of the court, related to the coordinates and I will map them. To this aim I will use the Pandas groupby utility. I will do it step-by-step for clarity. So let’s first deepdive a bit into groupby dataframes and how they can be used, before actually using them for further visualisation. Let’s group by shot_zone_area. We can then iterate on the groupby dataframe by the column we used to group items on and the rest of the dataframe, as shown next. The following block will show us the different values of the column we grouped by, and the length of each corresponding division in the rest of the dataframe.

Next, I will define a method that takes any of the area features as an input and groups by the given feature. I will get a Numpylinspace of equally spaced points with length equal to the groups created by the given feature’s groupby. This will be used to pick a color for a colormap for each one of the groups. Finally we will iterate on the groupby dataframe as above, assigning to each group a different color using zip. Note that in the groupby dataframe, we need [1] to access the rest of the dataframe, as [0] is the groupby feature. You can choose from a selection of Matplotlib palettes.
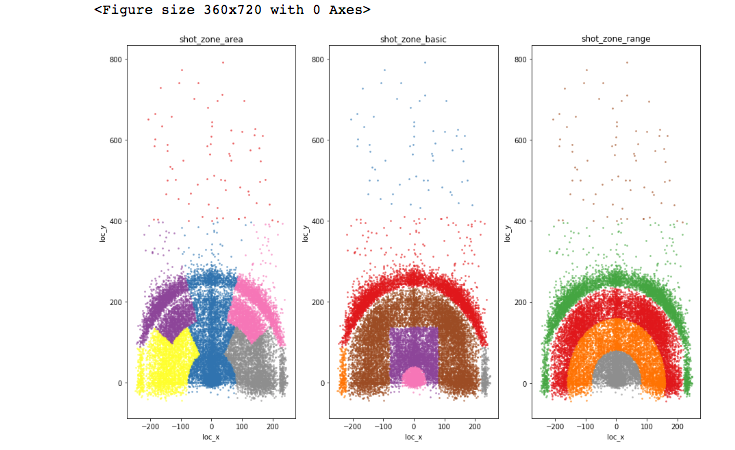
You will find this type of graphs quite frequently in Kaggle’s forums as part of the discussion around a competition.
After familiarising with the basics of the dataset, I will now use Tableau in order to double down on the dataset and make it as transparent as possible. As mentioned before, you can achieve the same results with Python.
Here’s an intuition: Roughly speaking if there is “enough” variation of the target variable’s distribution across “buckets” defined by a feature (i.e. the feature’s different values), this could be an indication that the feature is predictive of the target variable. Let’s discuss this point more…
First, take it with a grain of salt: A relatively even target variable distribution does not necessarily mean that the feature is not predictive. The distribution might be more variable in a subset of the dataset (we are currently examining the entire set). Depending on the modeling algorithm and the subsets it creates in the process, a feature might prove to be predictive. Think about this for a moment.
Conversely, it may happen that a target variable distribution varies across the values of a feature but the feature will not make its way into a good predictive model. When? Simply, if it is dependent or correlated to another feature. In that case, it would possibly just add to overfitting. As an example of dependent features, the area variables are mappings of the coordinates, as we showed earlier in the Jupyter notebook. Strictly speaking the empirical intuition of a “enough variation” can be statistically tested.
Now, let’s examine how shot_made_flag distributes against some of the features. You don’t need to check each feature, I just want to show ways of making the dataset completely transparent and build good intuition. I will return to assess these intuitions in retrospective when I build and evaluate the model later on.
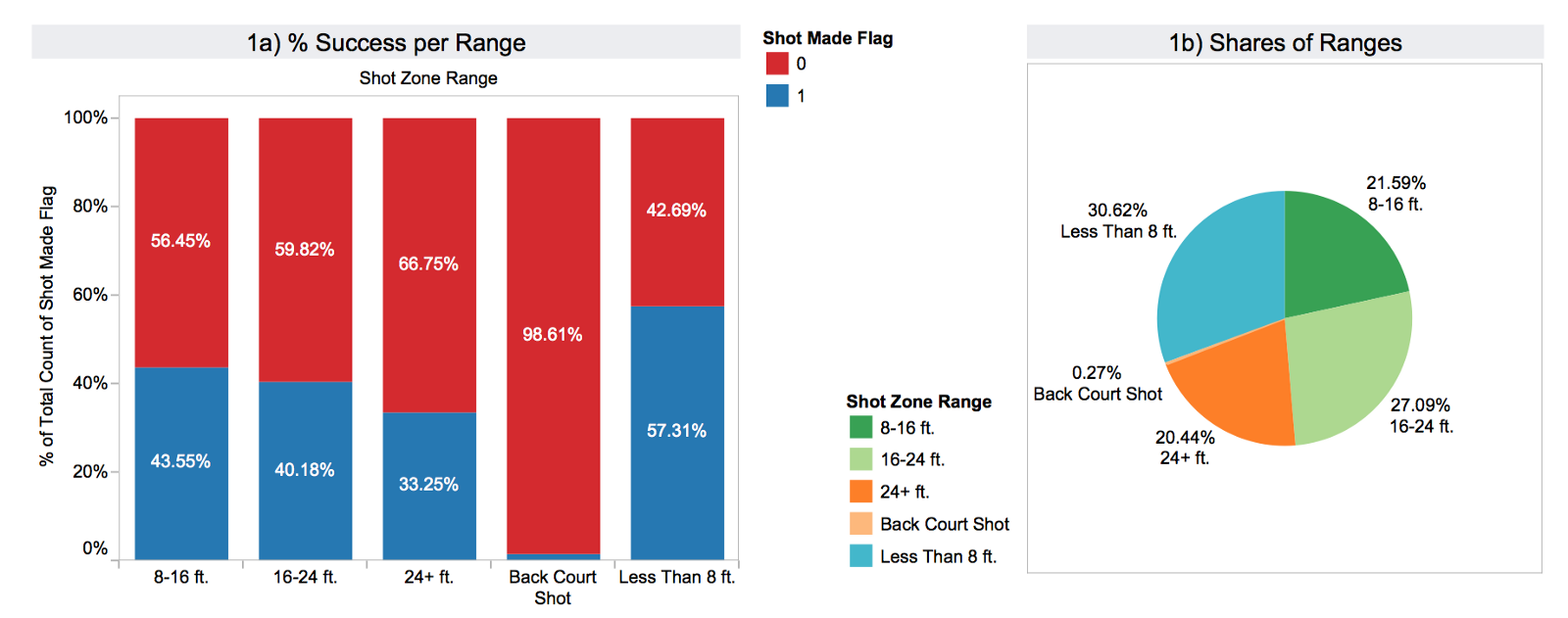
In the next graph you can see theshot_zone_range distribution. The scored shots are represented with blue and the failed attempts red. Apparently, the target variable is unevenly distributed across the subsets defined by the range feature. The pie graph on the right (1b) shows how many shots there are in each bucket in total.
In the second graph, the blue line represents scored shots per shot_distnace. The distance is in feet and one can see the steep increase at the limit of 22–23 ft. where the 3 pointer line lies. The red line shows the number of failed shots. 3a) shows the success ratio for the 2 and 3 pointers. Finally, 3b) is the share of total 2 and 3 pointers attempted (shot_type).

All the above features are correlated, which means that not all will make it to the predictive model. Distance and x/y coordinates are a different representation of the independent variable. The rest are mappings of the distance.
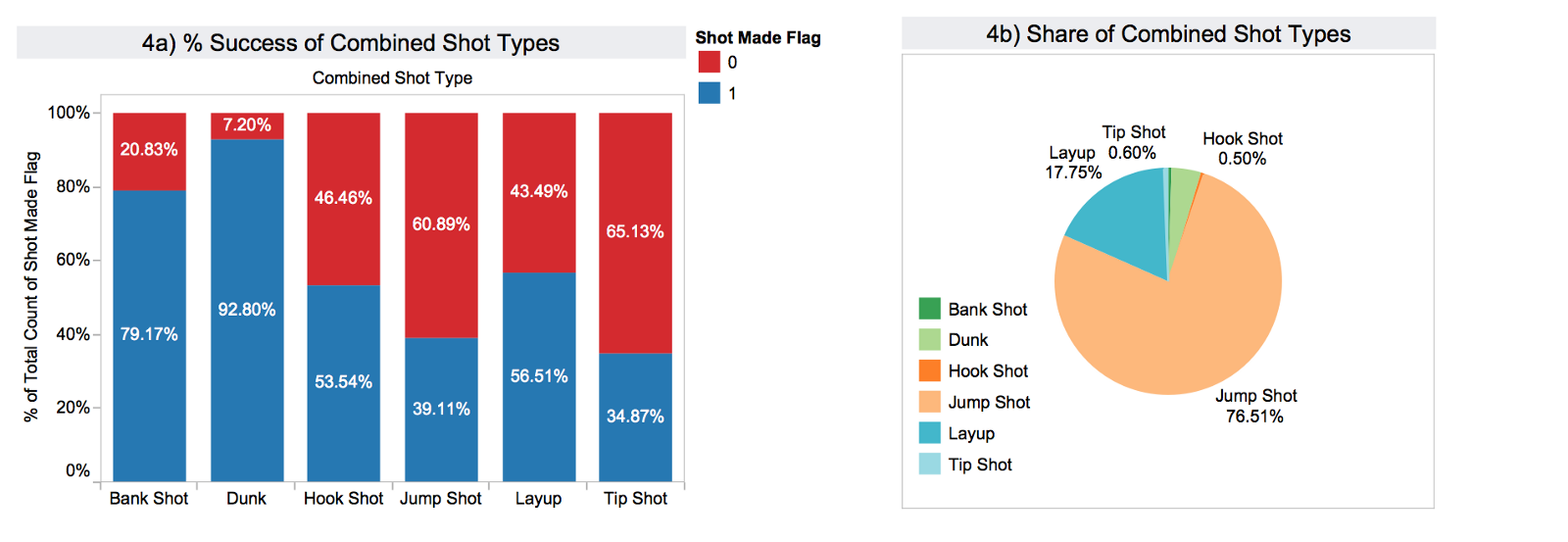
In graph 4) it becomes evident that the target variable is distributed unevenly across the combined_shot_types as well.
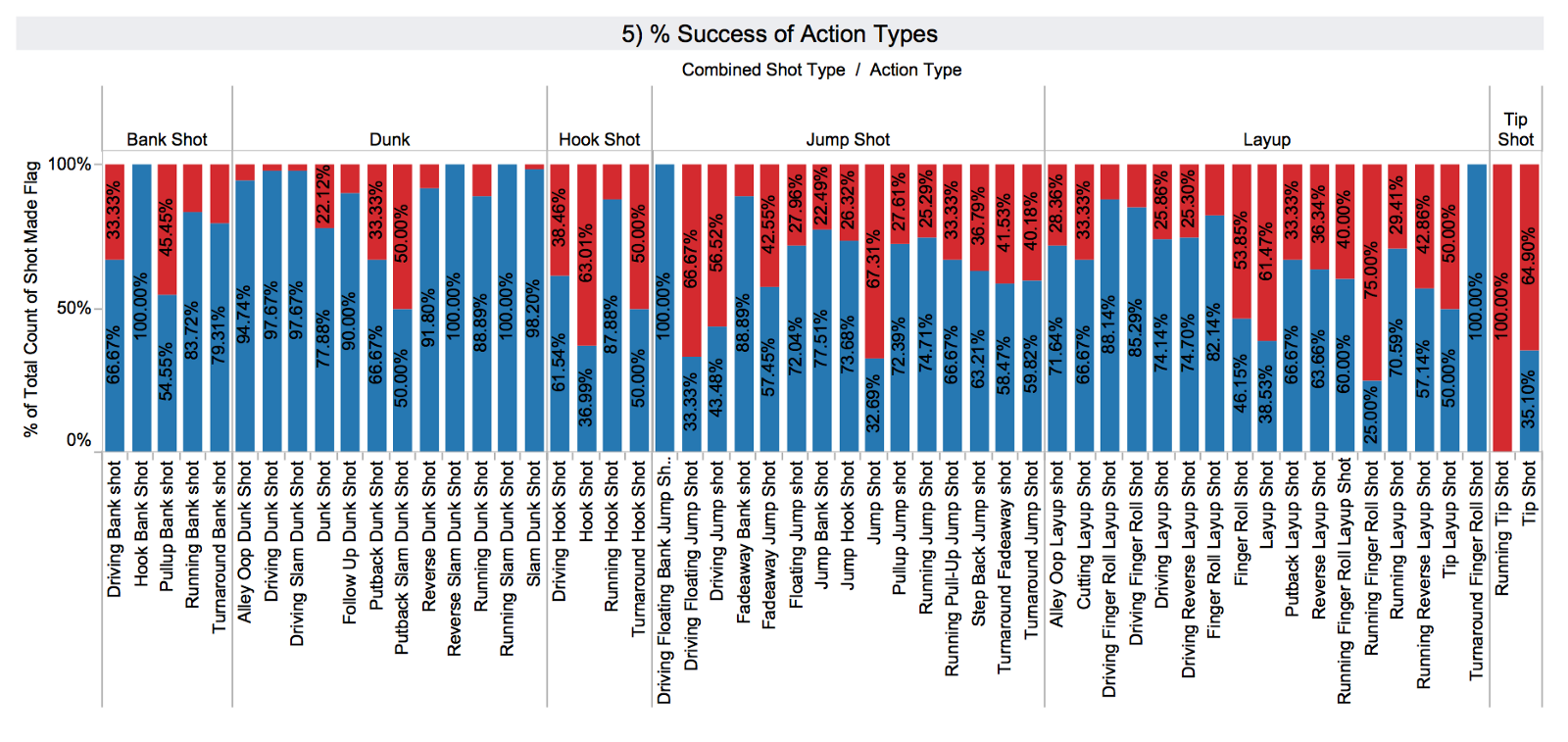
In 5) one can observe that action_type is a more fine grained categorisation of the combined_shot_type. Again there is notable variability, and so I expect that action_type is a good candidate for the predictive model.
In 6) I have summarised the performance per period of the game and the share of shots in each period. Here we see a more even distribution.
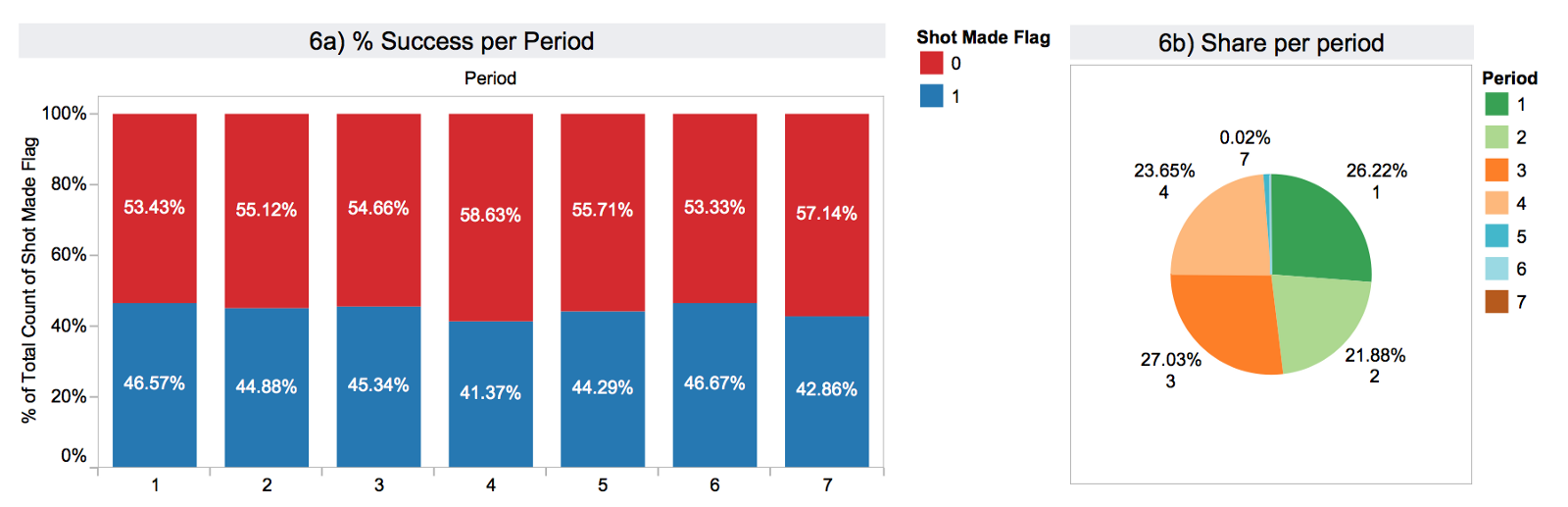
Graph 7) illustrates the calculated field remaining_time until the end of the period.

I think that you get the point already, so I’ll skip visualising the rest of the variables. At this point, we have a full understanding of our dataset.

4. Modeling with a decision tree
For the actual modeling part, I will use a decision tree for two reasons:
- Decision trees are easily interpretable.
- They can be used as a baseline that performs well in order to compare with more advanced models, like Random Forests, Neural Networks etc. They have the additional advantage that you may skip standarisation, normalistaion, feature extraction etc. and other pre-processing steps (I will explain why next) required by other algorithms.
Decision trees work by splitting the sample space into purer segments. The criterion that we will use for splitting is entropy (although you can also use gini). Entropy is defined as follows:
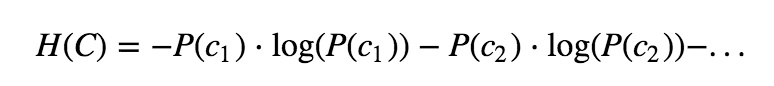
where P(c1) is the probability of class c1 in the segment and so on. In a problem with two classes, a pure segment (having either only class c1 instances or class c2) has entropy 0.
Next, I will show the following in the context of decision trees:
- Pre-processing, which consists of data cleansing and dummification of categorical features. As mentioned earlier, for other algorithms you may need to perform additional pre-processing steps.
- Predictive modeling: I’ll start by determining the complexity of the tree to avoid overfitting. I will use an initial method to narrow down the area and then perform k-fold cross-validation to pick the optimal complexity. Then, I will train, test and evaluate the model across most typical metrics, i.e. accuracy, precision, recall, f1-score.
- Visualisation: I will visualise the bias/variance sweetspot, the tree itself and the feature space divisions that it creates.
5. Pre-processing
5.1 Cleaning the dataset
First, let’s drop all lines where the target variable is NaN.

Let’s start by examining the temporal features. They are relevant as follows:
Game_datemay capture performance variability based on the point in a season (e.g. month etc).- I’ll break
game_dateinto month and year. Season(and the year component ofgame_date) may capture the effect of aging in the player’s performance.- Finally, I’ll use
time_remaining(in seconds) and dropsecondsandminutes_remaining.
The shot_id and game_id may be useful for time series analysis, but for now we can drop them. Team_name is always L.A. Lakers, so we can drop it as well.

Part of the matchup information is in opponent. However, we want to capture the home/away property. We will create a series with 1s where there is ‘vs.’ in the field (apparently corresponding to home games) and 0s elsewhere (‘@’ apparently corresponding to away games). I will then drop the matchupand append the binary series:

Now, there is a question pending from earlier on: Why do we have loc_x, loc_y and lon, lat in the dataset? Let’s check whether they are redundant, “mirrored” data as we assumed in previous steps. A simple way to do this, is to compute the correlations between the variables loc_x and lon, and loc_y and lat respectively.

Evidently the variables are pairwise correlated 100% and thus one of the two pairs is redundant. Seaborn provides with a particularly convenient pairwise feature visualisation. We can use it to confirm the above visually.
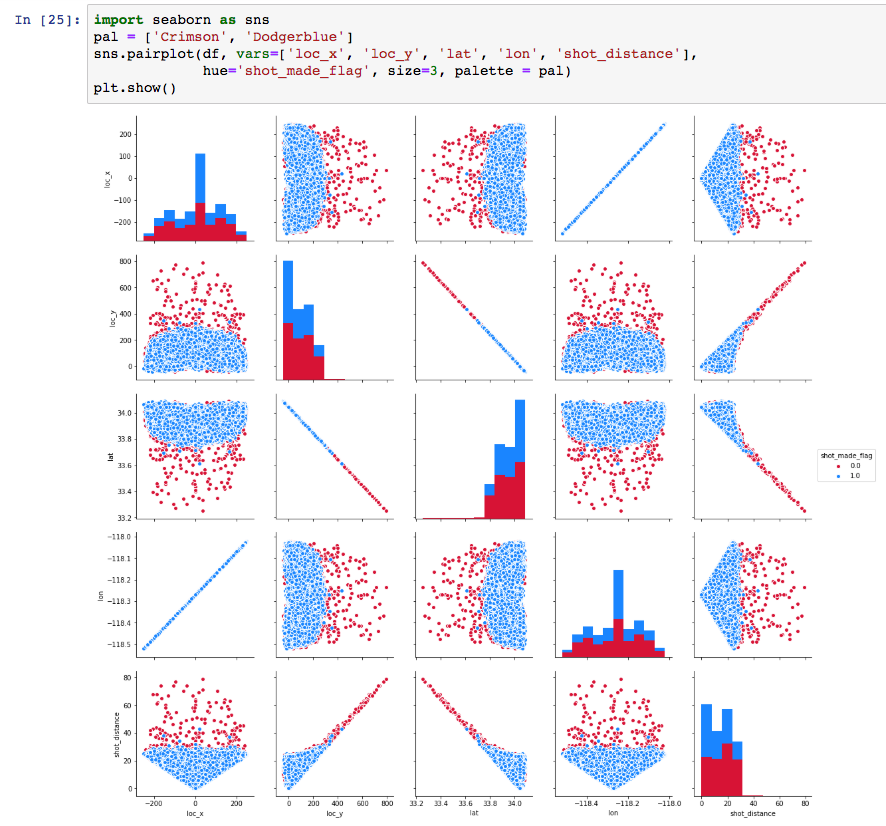
We will drop lon and lat and check the schema of the dataset before going further.

Good Data Science Note: Strictly speaking, we should only draw these insights by looking into the training set, not the entire set. By looking into the entire set we are slightly “cheating”.
In fact, theshot distance and angle features are sufficient to represent the spatial properties of a shot. The angle feature is captured by one of the two pairs of coordinates; The player may shoot better from certain angles, may be better shooting with one of two hands etc. Of course, retaining the coordinates and the distance features induces redundancy, but entropy based algorithms have an inherent feature selection property.
5.2 Splitting to training and testing set
So let’s now split the dataset.
Good Data Science Note: The pre-processing to be made on the training set will be applied to the test set as well but separately.
I will now isolate the target variable vector from the features and split the dataset to 80% training and 20% test set.

For the purposes of a tree classifier, features standarisation is not required. This is because trees do not work with any notion of distance, rather with class purity. In addition, we chose a tree classifier as our first model because of their interpretability and feature standarisation would compromise the model’s interpretability.
For the purposes of creating an angle feature though we will standarise loc_x and loc_y, to avoid zero values that may result in divisions by zero. With standarisation, the data are re-distributed around a mean of zero in one standard deviation distance.
Good Data Science Note: Once again, this processing must be done in training and testing separately.
Technical Note: Scikit’s
StandardScalerprovides with the facilities to transform training and testing consistently.

Next, we apply the same transformation to the test set, by using the same StandardScalerobject.

We can now drop loc_x, loc_y from both subsets.

In order to use Scikit’s classifiers, we need to convert the categorical fields. This can be achieved with Pandas’ get_dummies().
Technical note: Alternatively Scikit’s
OneHotEncoderorLabelBinarizercan be used.
Let’s see how the Pandas method works. I will first get the list of all categorical columns (they are of type object). This can be done with select_dtypes().

What is interesting here is that in the general case, as mentioned before, we should not look into the test set at all when pre-processing. Thus:
- Encoding the categorical data should be done based on the training set. At this point, the schema of the training set is finalised.
- Then separately, like we did not know anything about it before, we should encode the categorical data in the test set.
- With Pandas’
setdiff1d()we can determine then which dummified columns are missing from the test set compared to the training set and add them with 0 values across all rows. - Finally, I will select from the training set the columns that are in the test set, in that same order.

6. The decision tree
6.1 High bias vs high variance: the sweetspot
I will now check what is a reasonable complexity for our model. A complex model overfits while a simple model is not predictive, so what is the sweetspot here? I will train tree classifiers of various complexities and visualise their performance on the testing and training set.
To do so, I’ll use the min_samples_leaf parameter of DecisionTreeClassifier which controls the minimum number of samples present at each leaf. The smaller this number is, the more complex is the corresponding model. For decision trees, I’ll use balanced sampling to prevent bias for the dominant class.

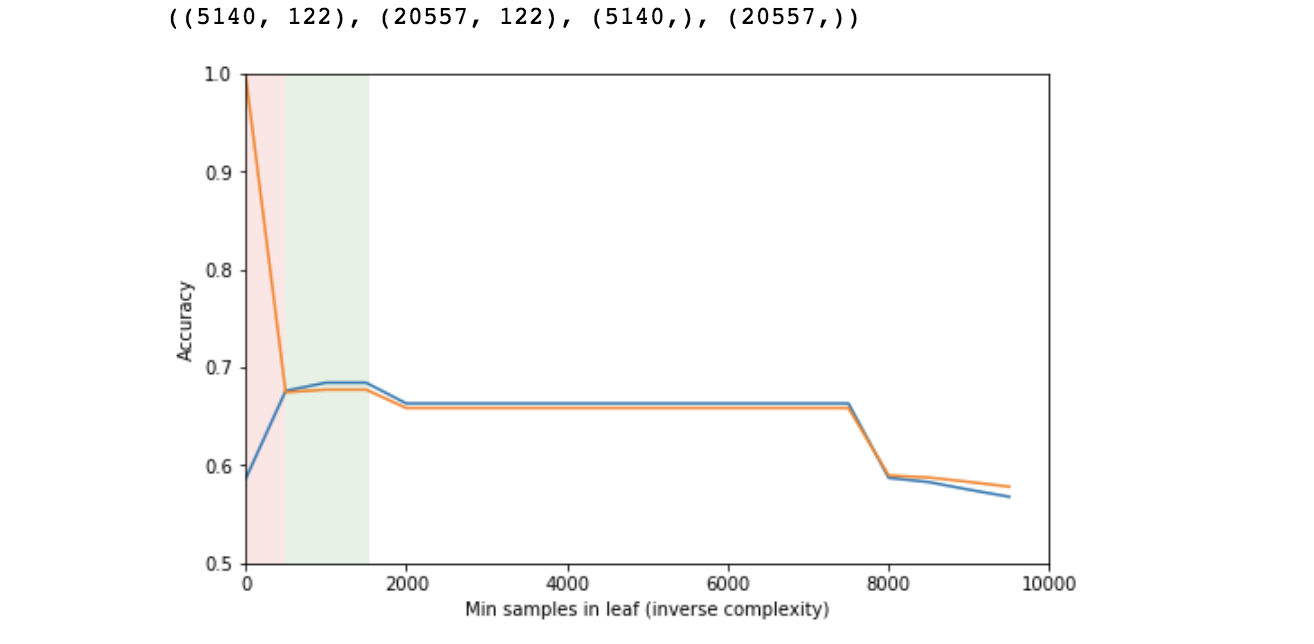
Good Data Science Note: In reality you should never evaluate the performance of a model on training data. Here, it is not part of the “real analysis”, it is only done for demonstrating the effect of overfitting and how accuracy varies vs. the model’s complexity in relation with overfitting. See next.
- The orange line represents performance on the training set and the blue on the testing set. Note that for small number of samples in each leaf (high complexity), the model performs very well on the training set and very poorly on the testing set (pink area). This is indicative of overfitting.
- At some point, the two lines converge and the sweetspot seems to be in the area of 500 to 1500 samples in each leaf (green area).
- Then performance diminishes as the model becomes simplistic (high bias).
This is the expected behaviour. This rough process is mostly for instructional purposes, but it also helps narrowing down an area of reasonable complexity, in which we can then perform cross-validation, a more expensive and accurate process, in order to pick an optimal value.

6.2 K-fold cross-validation
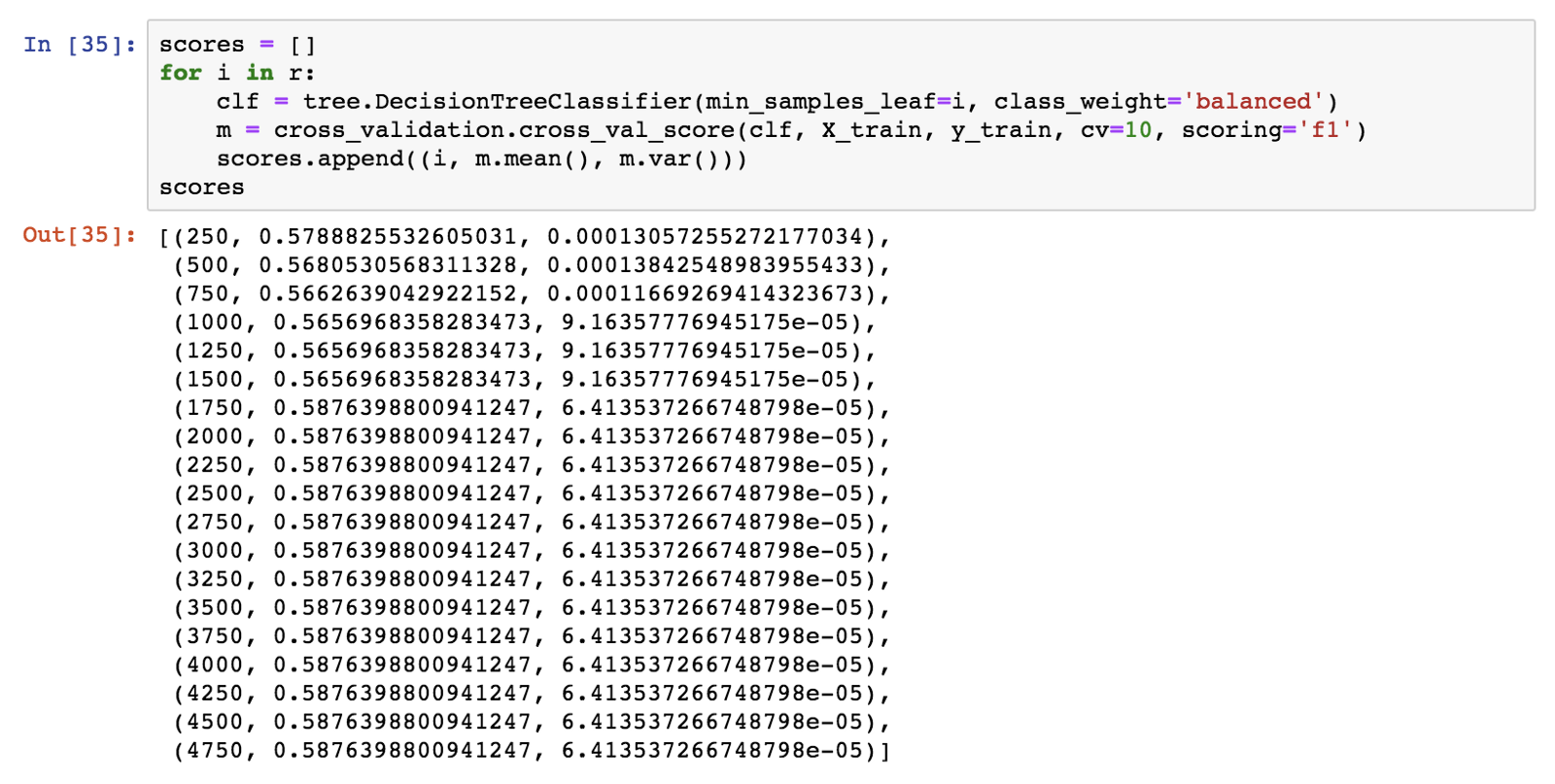
I’ll use 10-fold cross-validation in the area of 250 to 5000 minimum leaf samples value, in order to pick an exact value for use for our model. I’ll get the mean accuracy and variance of each cross-validation run.

I’ll use the f1 score to evaluate the models.
Good Data Science Note: f1 is preferred over accuracy as a model evaluation metric. Accuracy is not informative of false positive and negative rates which may not worth equal for particular applications and it may be misleading in case of very unbalanced classes (not the case here).
Technical Note: If despite that, you would like to use accuracy, declare it so in the
scoringparameter ofcross_val_score. Scikit learn provides with an array of alternative metrics.
6.3 Model and visualisation
The minimum number of 1750 samples maximises accuracy and f1. I will now train a decision tree with this value. Once more, sampling should be balanced, and the criterion will be the entropy.

I will now visualise our decision tree model. In the following graph, blue signifies scored shot prediction and orange represents a missed shot prediction. Lower entropy (corresponding to higher purity) is represented with darker colors.


Note that the tree is rooted at action type (jump shot). If you scroll back up to Tableau graphs 4 and 5), you will notice that we were expecting this feature to make it into the predictive model because the target variable varied quite a lot depending on it.
Also, note that jump_shot is the dominant type of action. These two combined mean that it creates divisions that maximise purity, so it is natural to be the first predictive feature that the model picks up. Single-feature trees (aka decision stumps) are often used as baseline classifiers, action_type_jump shot would be the feature for a stump.
For similar reasons, shot distance and season (year here) were also expected to make it high in the model. On the other hand, time remaining was not an apparent predictive feature.
It is interesting to see how the tree divides the feature space. A typical visualisation is pairwise feature comparison. In this case, we have many categorical and binary features and that does not help visualising, so I am just picking two significant numerical features, time_remaining and shot_distance and comparing how the model complexity affects the areas that the tree creates.
For visualisation purposes:
- I will train a tree classifier for various model complexities like before (more particularly minimum 250–1750 samples at each leaf), only this time with these two features only.
- I will plot the predicted areas with a contour: In the blue areas, the tree predicts that shot will fail, while in the yellow ones that the shot will go in.
- I will also plot the test dataset on top: Red points are actual missed shots and black ones went in.
- The subplots represent gradually simpler models. Note how the boundary becomes gradually simpler. For small minimum numbers per leaf, the tree overfits.


6.4 Model evaluation
Let’s calculate the tree’s accuracy:

Does this accuracy score beat the baseline majority classifier (a “classifier” that always predicts the dominant class), and if so by how much?

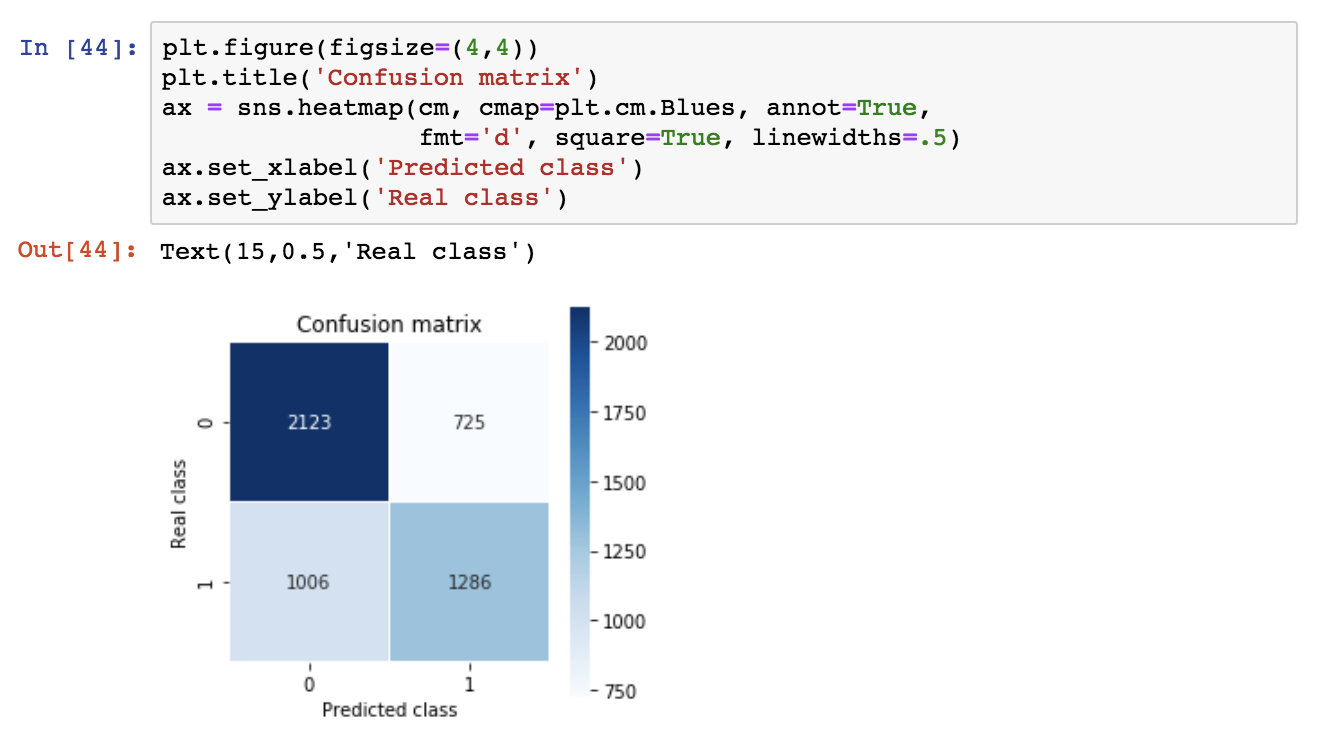
So, the decision tree is predictive with an accuracy ~0.66, a significant improvement over the baseline majority classifier which has an accuracy of 0.55. Let’s inspect the confusion matrix as well as the precision, recall and f1 score.

The y-axis is the real class, the x-axis is the predicted class and classes appear in ranked order (so 0, 1). According to this, we get a high number of false negatives (1006). For transparency, we can plot the confusion matrix.
Now let’s examine the precision, recall and f1 score:

7. Thanks!
If you made it all the way here, thank you for reading and I hope that you found it both useful and enjoyable.

